SparkFuzz - Searching Correctness Regressions in Modern Query Engines
While working with apache datafusion-comet, I came across a paper titled SparkFuzz. Datafusion-comet also has a tool inspired by SparkFuzz to test correctness.
Note - Theses are my notes from the paper. You will find things copied verbatim from the paper.
This tool generates random data and queries to test the correctness of query engines. It executes the queries on a reference database such as PostgreSQL which is ten used as a test oracle to check the correctness of the query engine (e.g., Spark SQL).
Modern query engines are complex and have many optimization techniques. Also, setting up a test environment for query engines is difficult because of so many configurations and dependencies. Testing becomes a multi-dimensional problem.
Hence, this paper suggest to use fuzz testing to test query engines. With fuzzing they are able to re-generate multiple queries and input datasets of different sizes. In contrast to traditional testing which support a few fixed queries running on a relatively small dataset.
Key Idea
SparkFuzz, an automatic test case generator for the Spark SQL engine.
It has three main components:
Columnar-Oriented Dataset Generation:
- SparkFuzz automatically generates datasets by randomly sampling supported data types to create table schemas and fill them with random data.
Recursive SQL Query Generation:
- SparkFuzz constructs queries using a recursive SQL model. It defines a “query profile” consisting of various operators and clauses.
- Each feature (operator or clause) is annotated with weights to calculate its probability of being sampled, ensuring diverse query generation.
- In addition to data and query generation, SparkFuzz can randomize the configuration space of a Spark deployment, adjusting optimization rules and parameter ranges.
Testing Modes:
SparkFuzz supports two testing modes:
- Comparison against PostgreSQL: Verifying correctness by comparing Spark SQL query results to a reference PostgreSQL implementation.
- Cross-instance Testing: Comparing results from different Spark SQL instances.
THE SPARKFUZZ FRAMEWORK
Design Overview
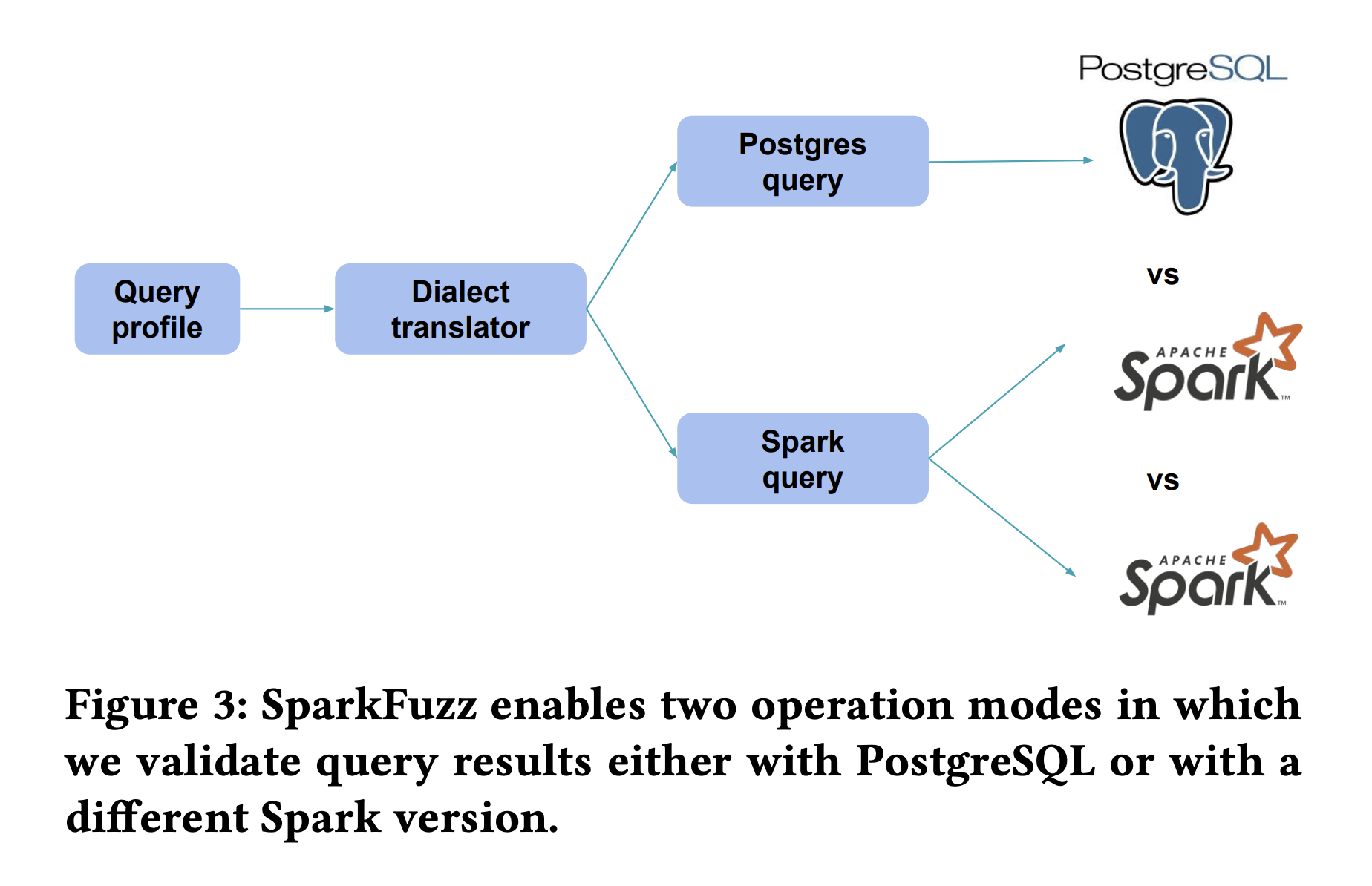
- Two testing modes:
- Compare Spark SQL results with a reference database (e.g., PostgreSQL) for strong correctness guarantees.
- Compare results across different Spark SQL instances (e.g., stable vs development versions or different configurations).
 source: SparkFuzz Paper
source: SparkFuzz Paper
- Testing approach:
- Randomly generate tables and construct multiple queries over them.
- This approach prioritizes rapid testing and high operator coverage, though it may miss deep, data-dependent bugs due to simplistic data generation.
Data Generation
-
File format support: SparkFuzz generates datasets in Parquet, Delta, CSV, and ORC, either user-specified or randomly selected.
-
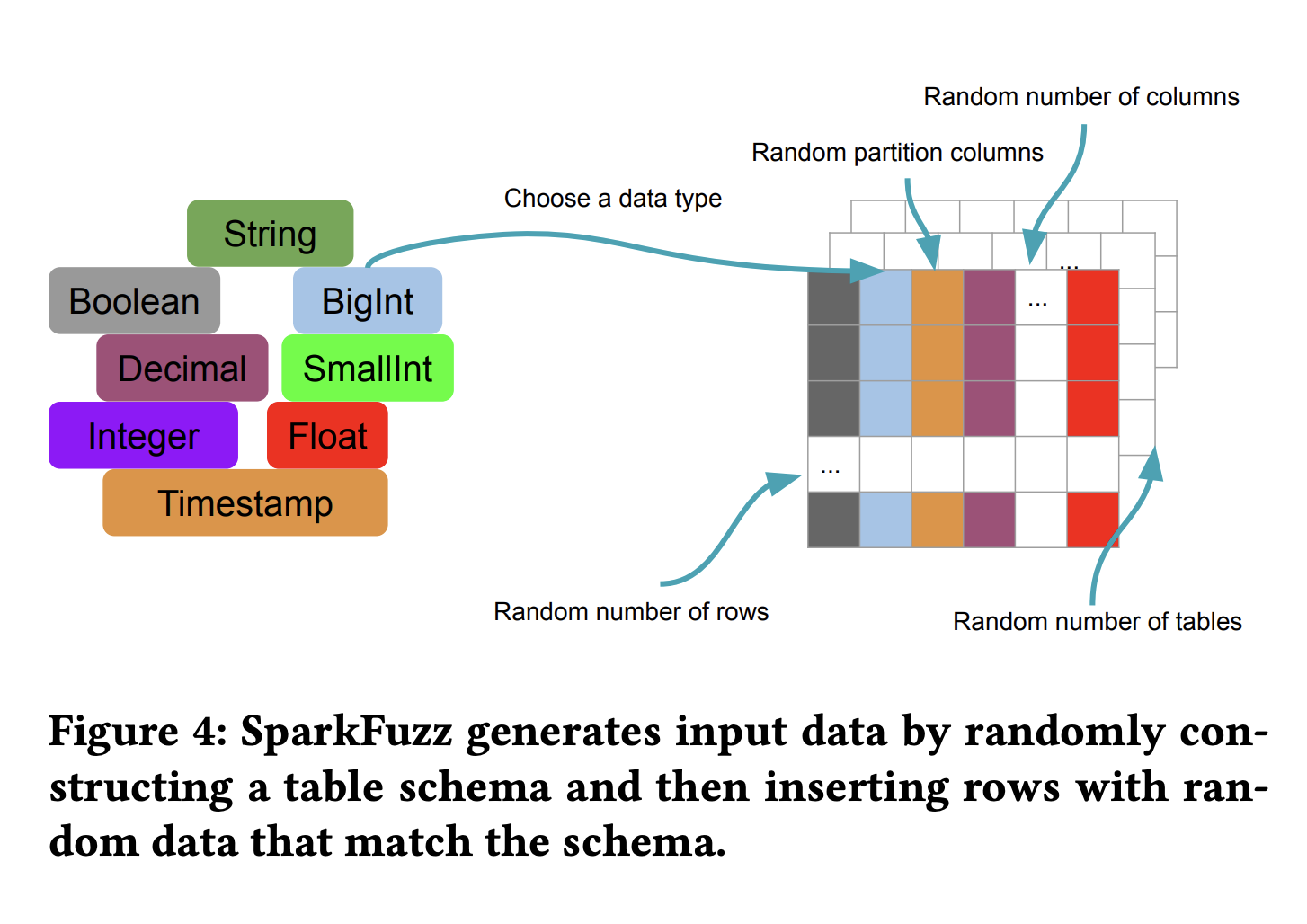
Random dataset generation steps:
- Randomly selects the number of tables (more tables for queries with multiple joins).
- Sets table dimensions by choosing the number of rows and columns.
- Constructs a random schema from supported data types and populates tables with random values.
- Optionally selects random partitioning columns for some tables.
 source: SparkFuzz Paper
source: SparkFuzz Paper
Query Generation
-
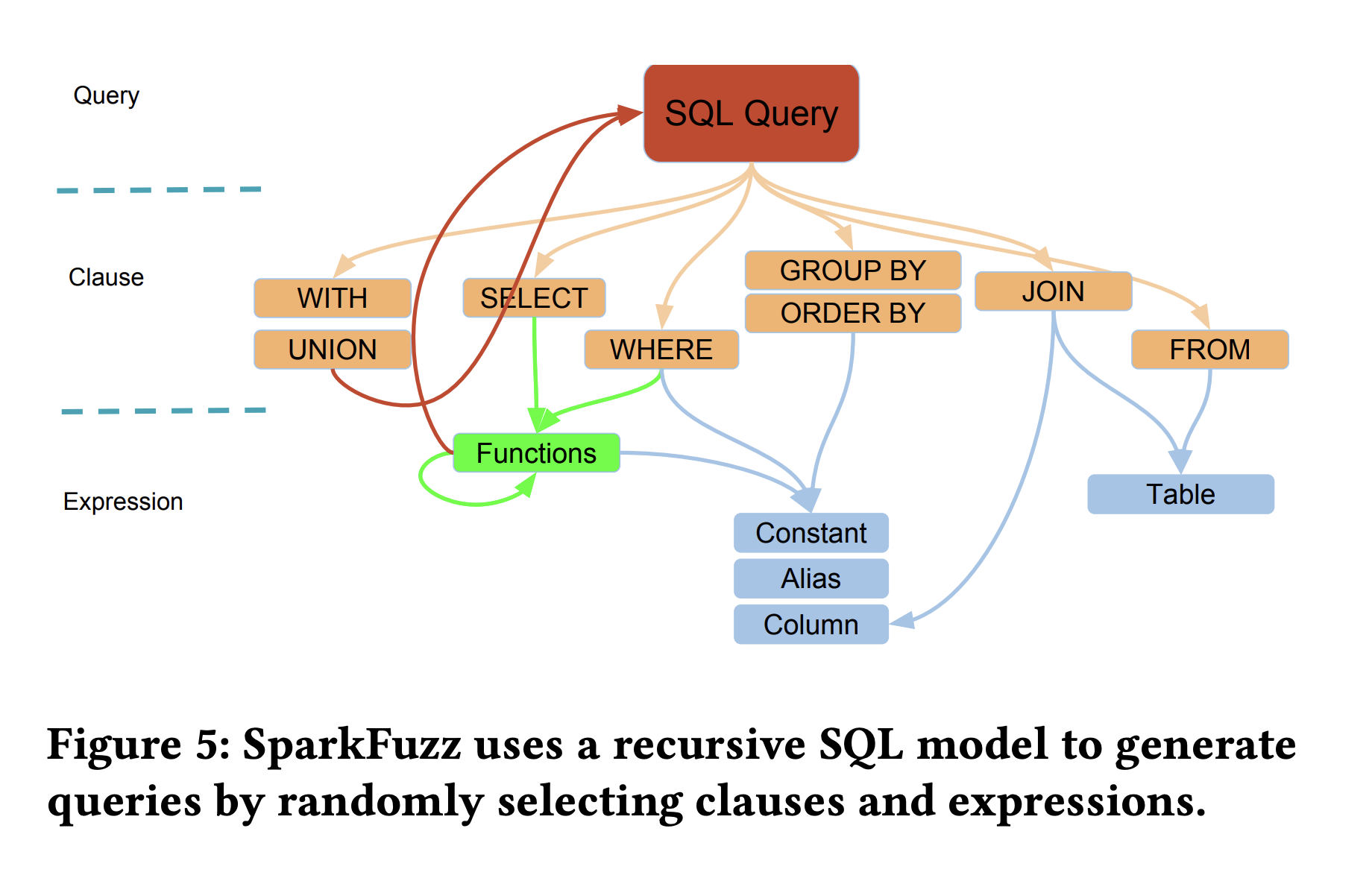
Query profile: Defines possible SQL features (clauses like
SELECT,FROM,GROUP BY) and their nested expressions (constants, columns, functions). -
Recursive model: Allows nesting of functions and sub-queries, supporting extensibility by adding new functions without changing the structure.
-
Probability-based clause selection: Each clause/operator is assigned a probability of selection. Mandatory clauses (
SELECT,FROM) have a probability of 1, while others can be blacklisted (set to 0). -
Inter-dependent weights: Used to select specific operators (e.g., join types or function classes).
-
Physical plan variation: Randomizes Spark configurations (e.g., broadcast size) to diversify physical query execution plans.
-
SQL dialect translator: Adapts generated queries to specific SQL dialects (e.g., Spark SQL vs. PostgreSQL).
 source: SparkFuzz Paper
source: SparkFuzz Paper