Distributed Training of Deep Learning models - Part ~ 1
Note: This post is part of a series on Distributed Training of Deep Learning models. Now, this is more like notes for me so you will find stuff copied directly from various places. Also, I use AI models to help with writing, as English is not my first language. I’m continuously learning and improving. If you spot any mistakes, feel free to correct me!
Introduction
Deep learning computations are typically represented as dataflow graphs by popular machine learning frameworks.
In these graphs, the edges represent multi-dimensional tensors, while the nodes correspond to computational operators, like matrix multiplication, which transform input tensors into outputs.
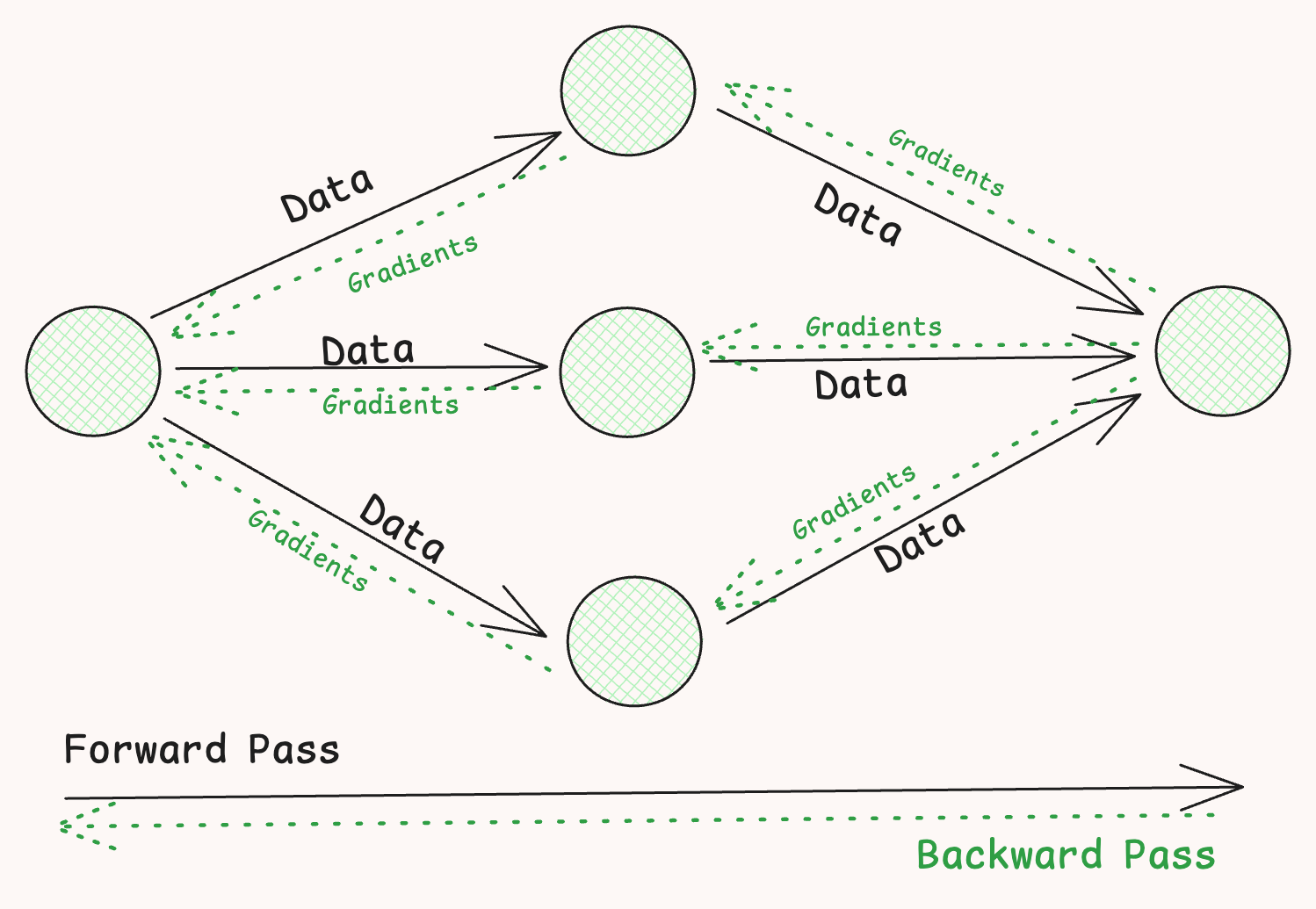
A single iteration of DL model training involves a forward pass of a batch of data, computing a loss, and then a backward pass to compute gradients which are used to update the model weights.
This process is repeated until the model’s loss reaches a global minimum.
Typically, model developers define the structure of the dataflow graph, and an execution engine optimizes and runs it on a GPU.
However, In today’s world, the size of the data and the complexity of the models have grown significantly. This has led to the need for distributed training of deep learning models.
Motivation
The world of AI is moving towards larger models. The larger the model, the better the performance, but higher the computational cost.
The following table shows the size of some popular models and the time it takes to train them on a single GPU. Reference
| Model Name | Size (Parameters) | Training Time (on Nvidia A100) |
|---|---|---|
| Resnet-101 | 45M | 44 hours |
| Bert-Base | 108M | 84 hours |
| GPT-3 175B | 175B | 3,100,000 hours |
A single GPU will take 355 years to train GPT-3 175B model.
Distributed training is becoming a necessity because of the following reasons:
- Developer/Researcher Productivity
- Shorter Time to Market
- Cost Efficiency
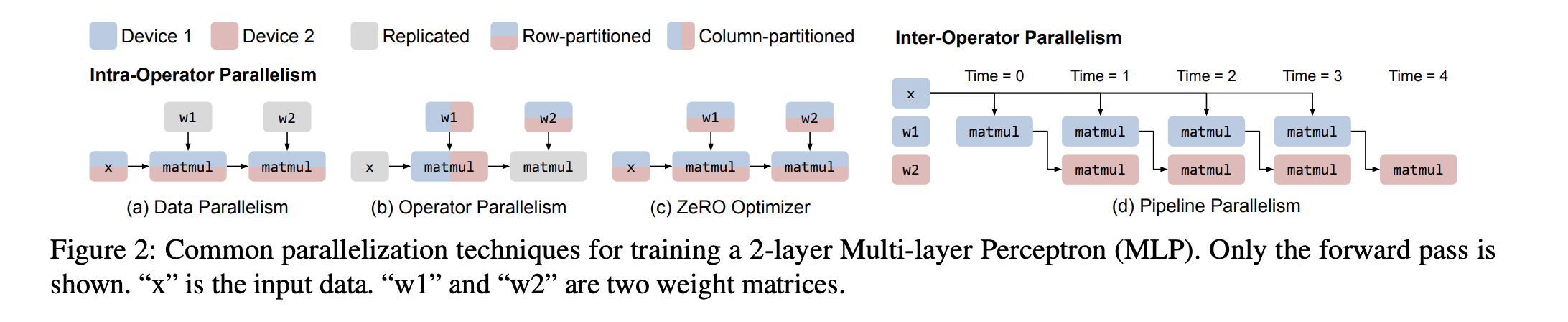
There are two types of parallelism that can be exploited to speed up the training of deep learning models:
- Data Parallelism (split data but model remains the same)
- Model Parallelism (split model itself across devices)
In this post we want to specifically focus on pipeline parallelism, rather efficient way to train large models.
Distributed Communication
AllReduce
There are some schemes to do collective communication in distributed systems -
- Scatter: Send tensor from one device to all other devices.
- Gather: Collect tensors from all devices to one device.
- Reduce: Similar to gather but with an operation like sum, average, etc.
- AllReduce: Perform reduce on all devices.
The goal is that we want a scalable alternative to bottlenecked parameter server approach. AllReduce is a way to do aggregation without a central server.
For i:0 to N:
AllReduce(work[i])
Time and Bandwidth complexity of AllReduce is O(N) because it is a sequential algorithm.
AllReduce is a sequential algorithm, we want better alternatives to this. Hence, AllReduce-Ring.
AllReduce-Ring
For i:0 to N:
send(src=i, dst=(i+1)%N, data=worker[i]) // send data to next worker
obj = recv(src=(i+1)%N, dst=i) // receive data from previous worker
worker[i] = merge(worker[i], obj) // merge data
Time complexity of AllReduce-Ring is O(N) but Bandwidth complexity is O(1). Each step performs a send and merge.
AllReduce - Parallel Reduce
Parallel for i:0 to N:
AllReduce(work[i])
Time complexity of AllReduce-Parallel Reduce is O(1) but Bandwidth complexity is O(N^2).
Can we do better than this? Can we combine advantages of AllReduce-Ring and AllReduce-Parallel Reduce?
AllReduce - Recursive Halving
For i:0 to log(N):
For j:0 to N/2:
send(src=j, dst=j+N/2, data=worker[j]) // send data to next worker
obj = recv(src=j+N/2, dst=j) // receive data from previous worker
worker[j] = merge(worker[j], obj) // merge data
For N workers, AllReduce-Recursive Halving has time complexity O(log(N)) and bandwidth complexity O(1).
Hence, AllReduce with proper algorithm can be very efficient and reduce the peak bandwidth requirement.
Model Parallelism
As far as I understand, Model parallelism is still an active area of research and not a solved problem yet.
There are some works which caught my interest like -
- GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism Paper
- Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning Paper
GPipe
GPipe Open-source library is implemented under the Lingvo [16] framework. The core design features of GPipe are generally applicable and can be implemented for other frameworks.
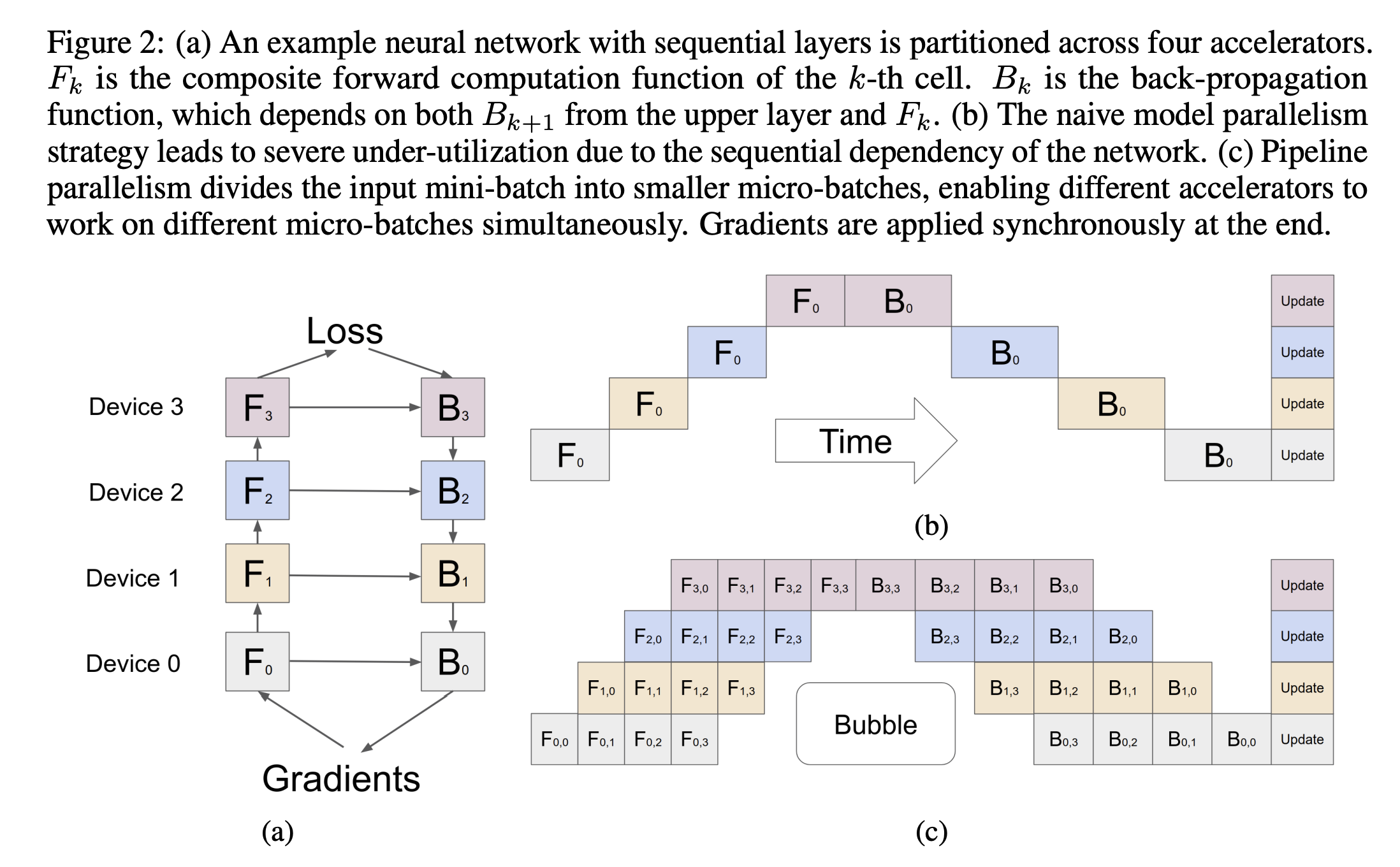 source: Paper
source: Paper
GPipe simplifies model parallelism for deep neural networks. It divides a network of L layers into K partitions, each with forward computation (fi) and parameters (wi).
Users specify:
- Number of partitions (K)
- Number of micro-batches (M)
- Layer sequence and definitions
This approach allows easy scaling across devices, optimizing parallelism and resource use. An optional cost estimation function (ci) aids in resource allocation planning.
Algorithm
GPipe’s workflow:
- User defines network layers (wi, fi, ci).
- GPipe partitions network into K balanced cells across accelerators.
- Forward pass: Mini-batch (size N) split into M micro-batches, pipelined across K accelerators.
- Backward pass: Gradients computed per micro-batch, then accumulated and applied.
- Batch normalization: Statistics computed across micro-batches and replicas.
This automated process optimizes pipeline synchronization and communication, making GPipe efficient for distributed deep learning.
GPipe also introduces low communication overhead, given that they only need to pass activation tensors at the partition boundaries between accelerators. Therefore, they can achieve efficient scaling performance even on accelerators without high-speed interconnects.
GPipe improves on Mesh-TensorFlow.
Mesh-TensorFlow:
- SPMD programming model (Single Program, Multiple Data)
- Extends SIMD to multiple tensor dimensions
- Splits computations across devices
- Scales matrix multiplications linearly with accelerators
- Increases model parameter capacity per layer
Limitations:
- High communication overhead (frequent AllReduce operations)
- Requires high-speed interconnects between accelerators
- Limits scaling performance on accelerators without high-speed interconnects
- SPMD limits the type of operations that can be parallelized
GPipe introduces pipeline parallelism by splitting mini-batches into micro-batches, processing them in parallel across accelerators, and applying a single synchronous gradient update.
This minimizes overhead and allows linear scaling with minimal communication between partitions. While it assumes each layer fits in an accelerator’s memory, GPipe is efficient even without high-speed interconnects. Handling layers like BatchNorm during training and evaluation requires special strategies.
GPipe offers near-linear speedup as the number of devices increases. It is flexible, supporting any deep network structured as a sequence of layers. Additionally, GPipe ensures reliable training by using synchronous gradient descent, maintaining consistency across partitions.
Alpa : Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
This paper introduces Alpa, a system that automates inter- and intra-operator parallelism for distributed deep learning.
Note: I have only done first reading of the paper, so I might not have understood or read everything correctly, especially the mathematical part.
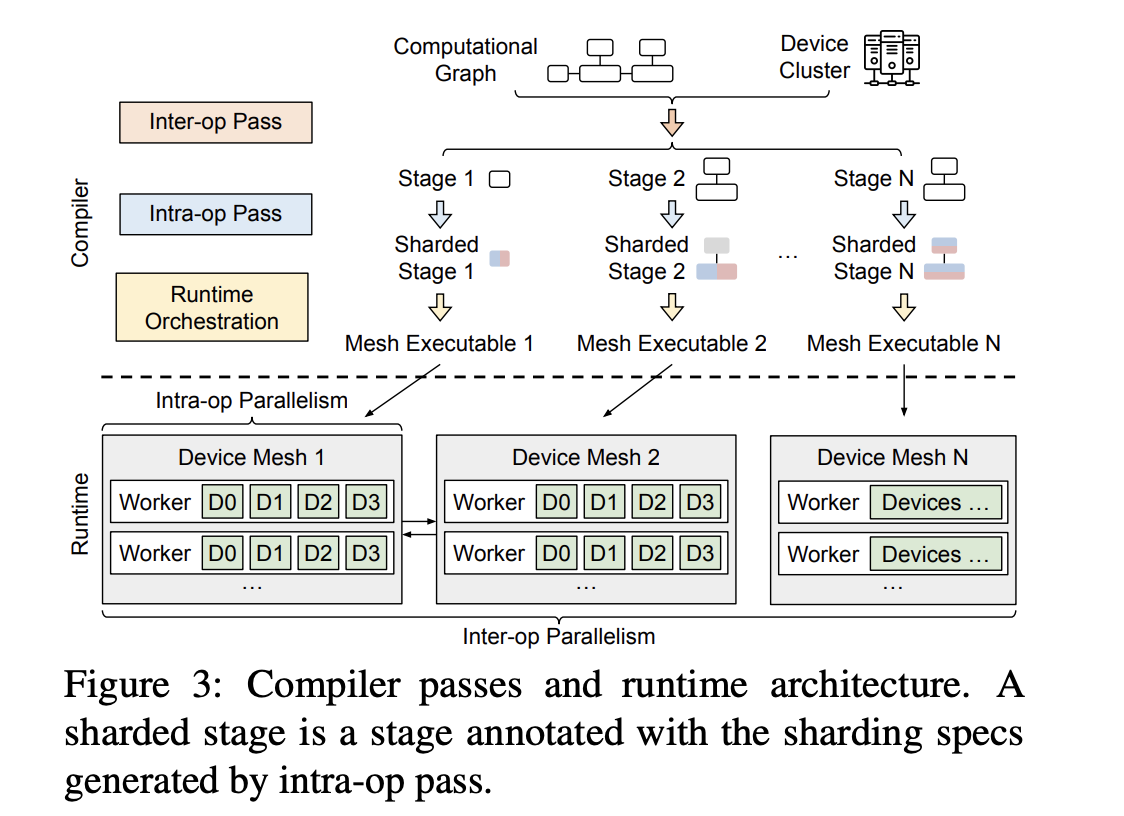
Alpa distributes the training of large DL models by viewing parallelisms as two hierarchical levels: inter-operator and intra-operator parallelisms.
The key idea is that parallelization techniques can be organized hierarchically and mapped to the compute cluster’s structure. Different techniques have varying communication bandwidth needs, while clusters have a similar hierarchy: nearby devices have high bandwidth, and distant ones have limited bandwidth.
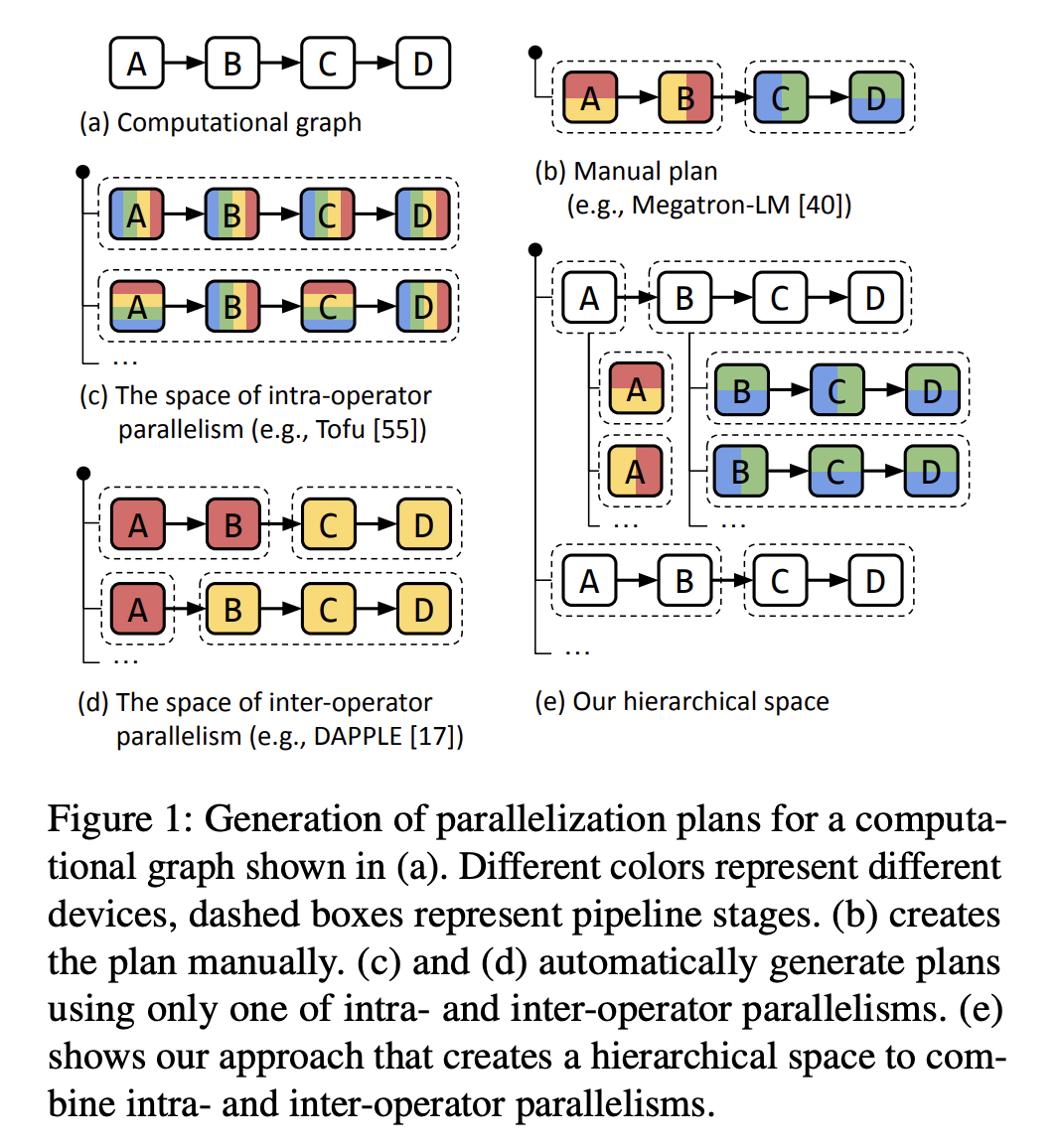 Source: Paper
Source: Paper
Inter-Operator and Intra-Operator Parallelism
Intra-operator parallelism splits ML operators along tensor axes and distributes the partitions across devices, while inter-operator parallelism divides the model into stages and pipelines their execution on separate devices. The key distinction is whether operators are partitioned.
Intra-operator parallelism improves device utilization but requires communication at every partition split and merge, while inter-operator parallelism limits communication to adjacent stages but may cause idle time. By leveraging the cluster’s asymmetric communication bandwidth, intra-operator parallelism is mapped to closely connected devices, and inter-operator parallelism is assigned to more distant devices.
This hierarchical approach simplifies optimization at each level, yielding strong empirical performance in training large models, though not globally optimal.
In summary, the paper’s contributions are:
- Create a two-level parallel execution plan space, using inter- and intra-operator parallelism hierarchically.
- Develop optimization algorithms that derive near-optimal plans at each level.
Alpa, a distributed DL compiler for GPU clusters, which includes:
- compilation passes that generate execution plans with hierarchical optimization,
- a runtime architecture for managing inter-op parallelism across device meshes, and
- system optimizations to enhance compilation and cross-mesh communication.
Workings of Alpa
Here’s a summary of how Alpa works:
- Hierarchical Optimization: Alpa optimizes model-parallel execution at two levels:
- Intra-operator Parallelism: Minimizes the cost of executing a stage (subgraph) on a device mesh (group of devices with high bandwidth).
- Inter-operator Parallelism: Minimizes latency by slicing the model into stages and mapping stages to device meshes.
- Compilation Passes:
- Inter-op Pass: Slices the model into stages and assigns them to device meshes using a Dynamic Programming (DP) algorithm. It queries the intra-op pass for the execution cost of each stage-mesh pair.
- Intra-op Pass: Optimizes each stage on its assigned mesh using an Integer Linear Programming (ILP) formulation to minimize execution cost.
- Runtime Orchestration Pass: Manages communication between adjacent stages on different meshes, generating static instructions for execution.
- Execution: Based on the optimized hierarchical plan, stages are compiled as parallel executables and executed on the assigned meshes with the appropriate communication protocols.
# Put @parallelize decorator on top of the Jax functions
@parallelize
def train_step(state, batch):
def loss_func(params):
out = state.forward(params, batch["x"])
return jax.numpy.mean((out - batch["y"]) ** 2)
grads = grad(loss_func)(state.params)
new_state = state.apply_gradient(grads)
return new_state
# A typical training loop
state = create_train_state()
for batch in data_loader:
state = train_step(state, batch)
 Source: Paper
Source: Paper
Conclusion
Based on watching this video lecture series by MIT HAN Lab, I got introduced to the concept of distributed training of deep learning models.
This part focused on the motivation behind distributed training and the different types of parallelism that can be exploited to speed up the training of deep learning models.
The next part focuses more on communication strategies, gradient compression, and other techniques to make distributed training more efficient.
Let me know if you have any questions or suggestions in email.