Distributed Training of Deep Learning models - Part ~ 2
Note: I use AI models to help with writing. Now, this is more like notes for me so you will find stuff copied directly from various places. If you spot any mistakes, feel free to correct me!
Communication bottlenecks in Distributed Training : Bandwidth and Latency
In the previous post, we discussed the challenges of distributed training and how it can be beneficial for training deep learning models. In this post, we will delve deeper into the communication bottlenecks that arise during distributed training, specifically focusing on bandwidth and latency.
Motivation
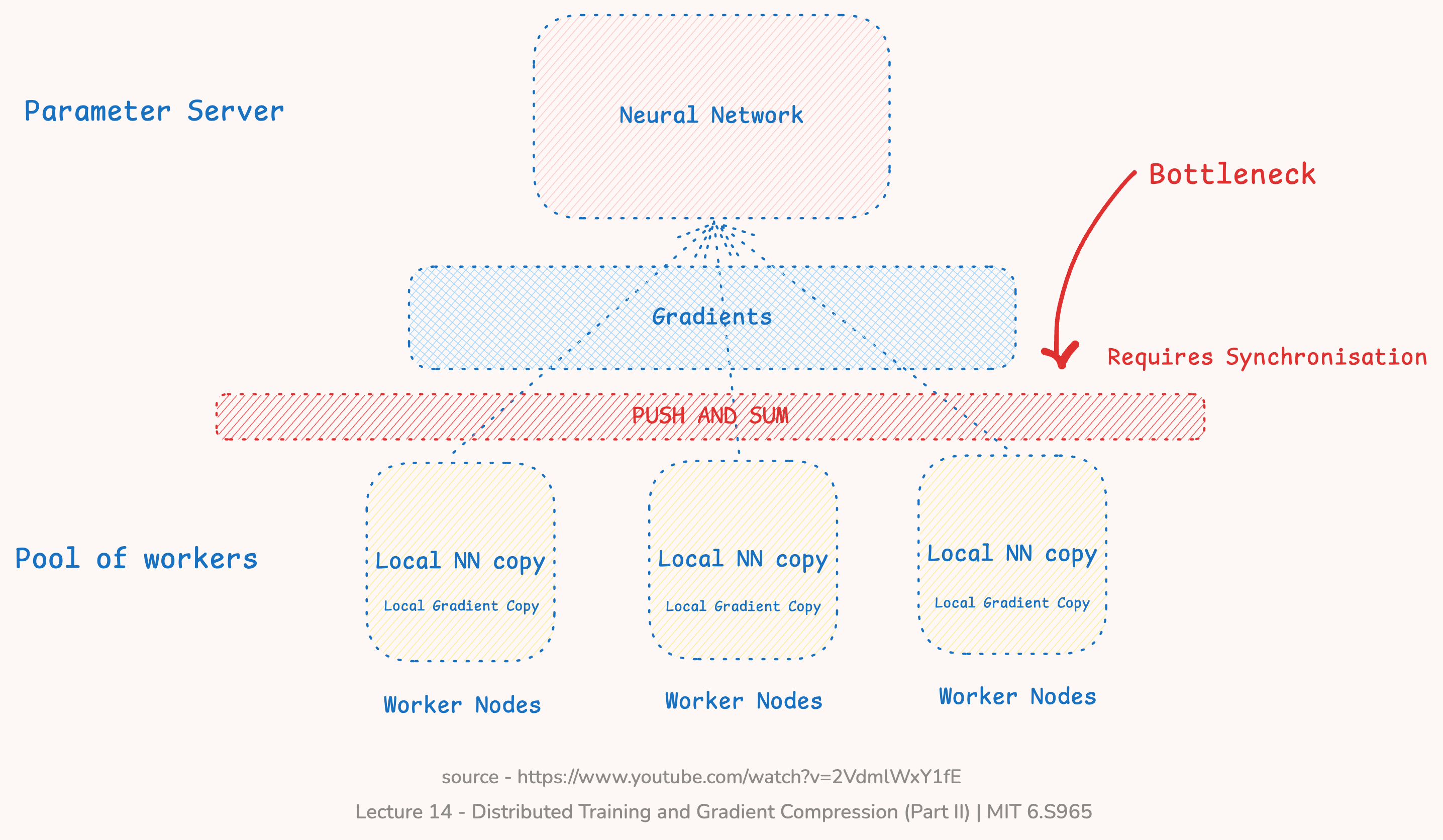
Parameter servers require frequent communication between workers and servers to update the model parameters. This communication can be a bottleneck in distributed training, especially when the model is large and the number of workers is high.
Larger the model, more the number of parameters, and more the communication and time required to update these parameters.
The network bandwidth becomes a significant bottleneck for scaling up distributed training. This bandwidth problem gets even worse when distributed training is performed on mobile devices, such as federated learning.
| Model Name | Size (Parameters) | Iteration Time (2080Ti, bs=32, ms) | Bandwidth (GB/s) |
|---|---|---|---|
| Resnet-18 | 11.69M | 137 | 2.7 |
| Resnet-50 | 24.46M | 330 | 2.3 |
| Swin-Large | 98.20M | 940 | 3.3 |
Normal ethernet bandwidth is around 1 Gbps, which is not enough to handle the communication between workers and servers. This can lead to a bottleneck in the training process, slowing down the training speed.
Gradient Compression : Tolerating Bandwidth
Gradient Compression reduces communication bandwidth, and in some scenarios, it can make training more scalable and efficient without significant loss in convergence rate or accuracy.
There are two types of gradient compression techniques:
- Gradient Quantization -
- 1-bit SGD
- 2-bit SGD
- TernGrad
- Gradient Pruning
- Sparse Communication
- Deep Gradient Compression
- PowerSGD
Gradient Pruning
Gradient compression leverages two key insights:
- In neural network training, only a small fraction of weights need significant updates per mini-batch, allowing delayed synchronization for near-zero updates.
- Gradients can be compressed by quantizing only values above a threshold, reducing bandwidth. Delayed gradients accumulate in a residual until reaching the threshold.
Sparse Communication
with local gradient accumulation
- send gradients with top-k magnitude
- keep the unpruned part as error feedback (residual)
- work for simple neural networks, but fail on modern models like ResNet.
Limitations of Sparse Communication
- Gradient dropping leads to poor convergence
Momentum is widely used to train modern deep learning models. However, gradient compression techniques like 1-bit SGD and 2-bit SGD do not work well with momentum. This is because the momentum term accumulates(in local buffer) the gradients over time, and the quantization error can accumulate, leading to poor convergence.
Hence we need to do momentum correction.
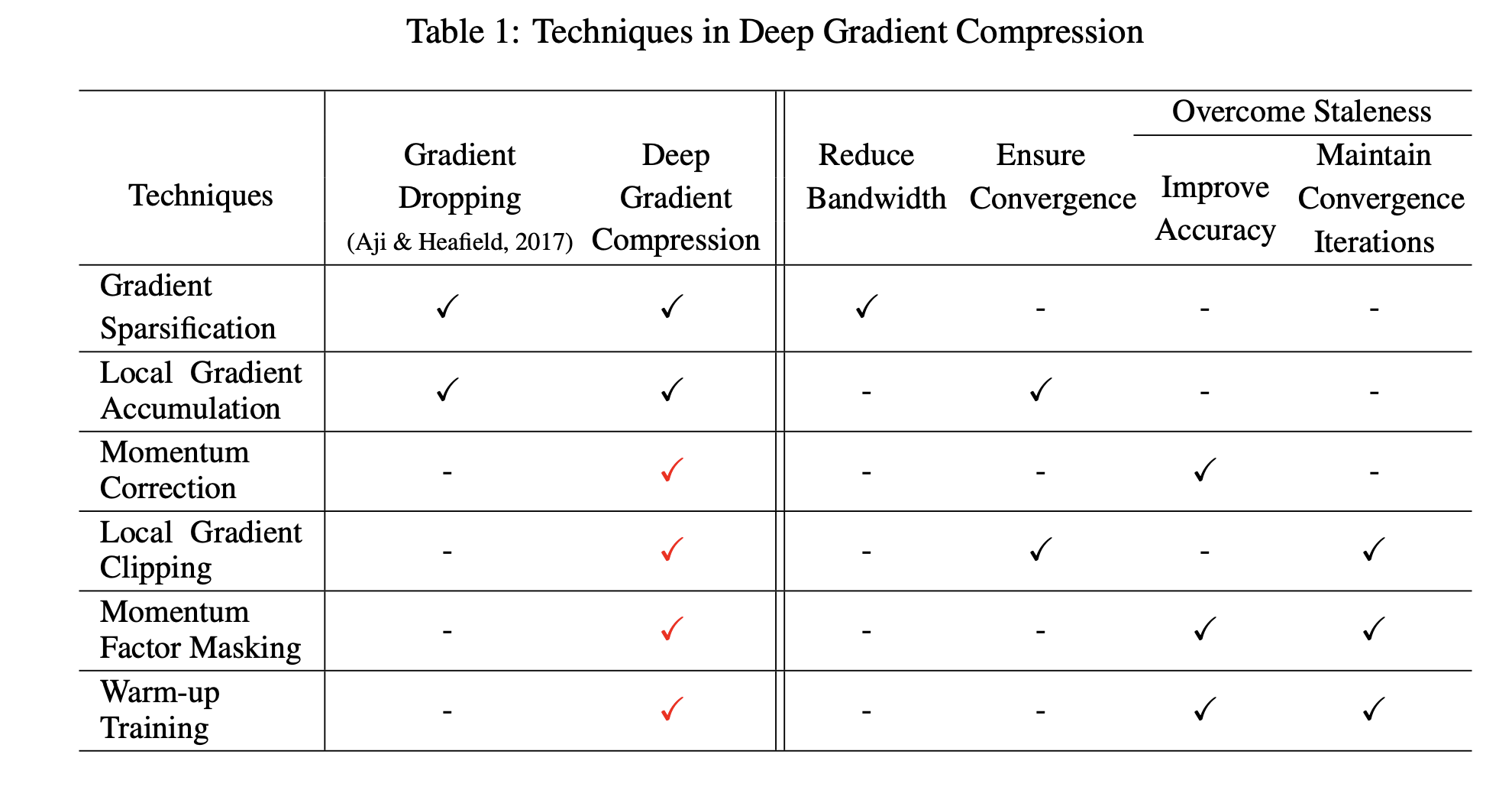
Deep Gradient Compression
This paper proposes a new gradient compression technique called Deep Gradient Compression (DGC) that works well with momentum. DGC uses momentum correction to reduce the quantization error and improve convergence.
It works on the idea of accumulating velocity instead of gradients. The velocity is the sum of gradients and momentum, and it is quantized and sent to the server. The server then decodes the velocity and updates the model parameters.
It basically comprises of three steps:
- Gradient Sparsification: Sparsify the gradients by keeping only the top-k gradients.
- Improving the local gradient accumulation: Use momentum correction and gradient clipping.
- Overcoming the staleness effect: Because we delay the update of small gradients, when these updates do occur, they are outdated or stale. To overcome this, we use a technique called Momentum Factor Masking and improvements in warm-up training.
 Source: Paper
Source: Paper
Comparing Gradient Pruning Techniques
Gradient Sparsification
- Local gradient accumulation
- Low Sparsity ratio
Deep Gradient Compression
- High Sparsity ratio while keeping the accuracy
- Gradients get denser doing all-reduce (problem)
PowerSGD
- Choose low-rank instead of fine-grained pruning
- Integrated in PyTorch
Gradient Quantization
1-bit SGD
This paper proposes a technique called 1-bit SGD, where the gradients are quantized to a single bit. This reduces the communication bandwidth significantly, but it can lead to poor convergence.
Two-Bit Quantization
- Uses 2 bits per gradient: 11 (positive ≥ threshold), 10 (negative ≥ threshold), 00 (others)
- 16 quantized gradients stored as one float
- Quantization error stored as gradient residual
Kvstore Types
- Device: Compresses GPU-to-GPU communication; increases GPU memory due to residuals
- Distributed (dist_sync, dist_async, dist_sync_device): Compresses worker-to-server communication; CPU handles compression and residual storage
- Server-to-worker and device-to-device communication remain uncompressed
Tolerating Latency
Latency is hard to improve because it depends on the physical distance between the workers and servers. However, we can tolerate latency by overlapping computation and communication. Traveling from Mumbai to San Francisco at the speed of light takes around 40ms, which is a significant latency.
High network latency slows federated learning. Conventional algorithms like SGD require frequent communication between the workers and the server, leading to high latency. Hence, we need to reduce the communication overhead to improve the training speed.
Can we allow delayed updates to reduce the communication overhead?
Delayed Gradient Averaging
This paper proposes a technique called Delayed Gradient Averaging, where the workers keep performing local updates while parameters are being updated on the server.
Conclusion
With this blog post we come to the end of the series on Distributed Training of Deep Learning models. In the previous post, we discussed the challenges of distributed training and the compute aspects of it. In this post, we focused on the communication bottlenecks that arise during distributed training, specifically bandwidth and latency. Also if you are interested in decentralized training of deep learning models, you can read the post third part.
References
- Lecture 14 - Distributed Training and Gradient Compression (Part II) - MIT 6.S965
- Sparse Communication for Distributed Gradient Descent
- Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
- 1-bit Stochastic Gradient Descent and Application to Data-parallel Distributed Training of Speech DNNs
- PowerSGD: Practical Low-Rank Gradient Compression for Distributed Optimization
- Delayed Gradient Averaging in Federated Learning