Decentralized Training of Deep Learning Models
In the previous posts we talked about Distributed Training of DL models Part 1 and Part 2. Now, in this post we will dive deeper into decentralized training of deep learning models.
Note: This is part of a series on Distributed Training of Deep Learning models. It’s a personal reference, with content copied from various sources. I use AI tools for writing, as English isn’t my first language. Corrections are welcome!
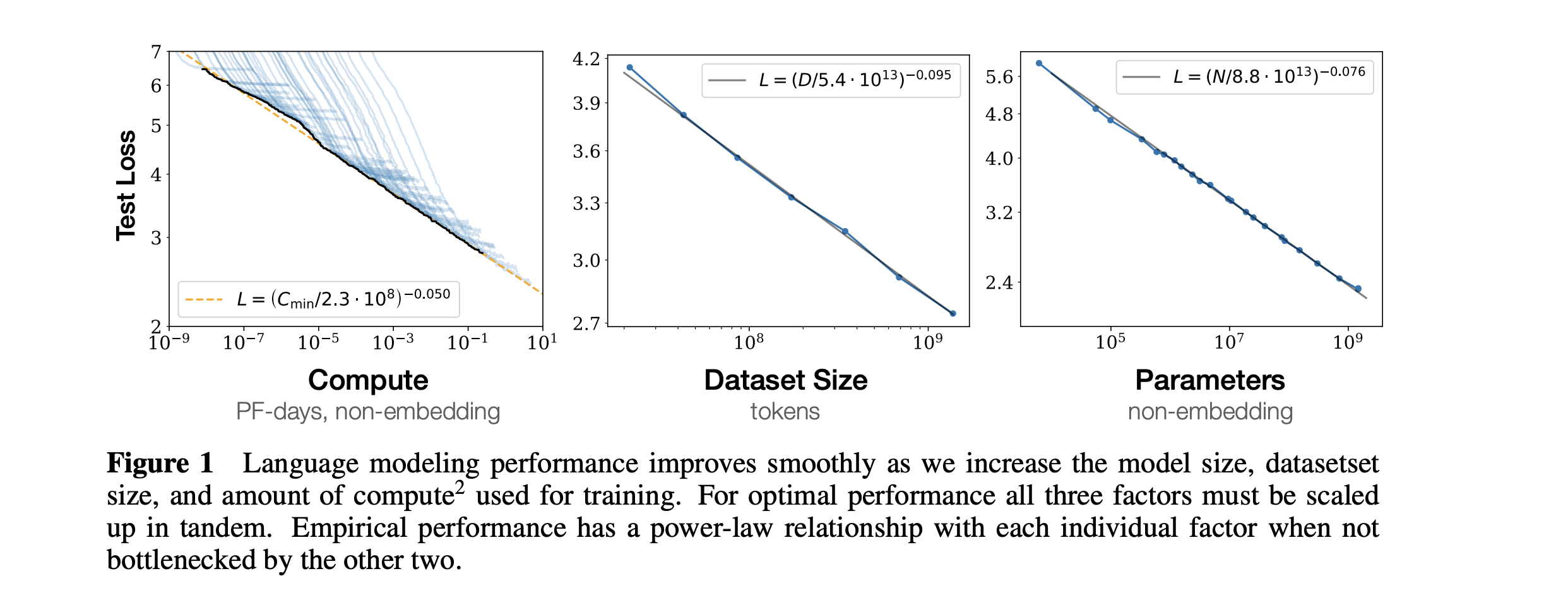
While reading Scaling laws for Neural Language Models, we get to understand about the empirical scaling laws for language model performance on the cross-entropy loss. The loss scales as a power-law with model-size, dataset-size, and the amount of compute used for training.
 source: Paper
source: Paper
The above paper show that model performance scales predictably with increases in model size, dataset size, and compute. Larger models and datasets improve performance according to power-law relationships, with bigger models being more sample-efficient. The paper provides guidance on balancing these factors to optimize compute efficiency in language model training. Maybe in future, we can discuss this paper in detail.
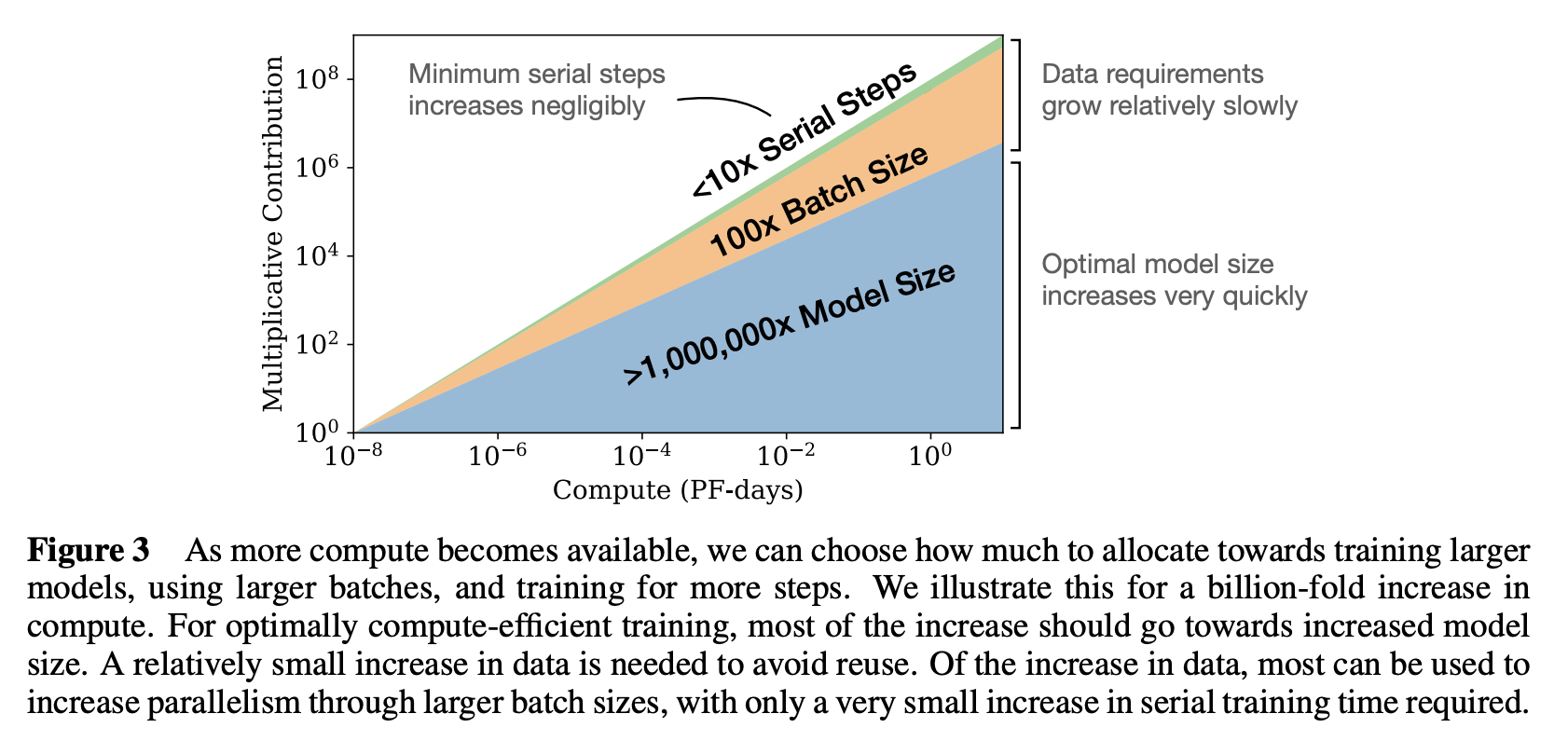 source: Paper
source: Paper
Introduction
In today’s world, we have two major challenges in training deep learning models:
- Building ML applications at SOTA scale is expensive. It requires millions of dollars in infrastructure and compute resources.
- Further scaling is facing non-linear bottlenecks. Diminished returns on throwing more money at the same problem.
Bottllenecks in Distributed Training
We have already discussed the bottlenecks in distributed training in a datacenter in the previous posts. The following are the bottlenecks in distributed training across non-co-located devices:
-
Communication bottlenecks: Bandwidth and Latency - If we want to scale further, we require fast connections. Today, model training is largely restricted to centralized data centers with high-speed interconnects. Very hard to use cheaper alternatives like spot instances or volunteer computing.
-
Data Quality: Increase of data volume often leads to a decrease in data quality. Open model are already facing this issue. If we want to scale further, we need to address this issue.
Decentralized Training
I have realized that if you want to quickly understand a paper around distributed/decentralized training, you need to understand how they are solving Optimizer math, Communication, and Synchronization.
Hence, our goal is to keep the convergence of SGD similar to centralized training while minimizing the communication overhead during decentralized training.
| Centralized SGD | Decentralized SGD |
|---|---|
| \(O\left(\frac{1}{\sqrt{nT}} + \frac{\epsilon}{\sqrt{T}}\right)\) | \(O\left(\frac{1}{\sqrt{nT}} + \frac{\rho}{T^{1.5}}\right)\) |
| Quantization error \(( \epsilon )\) affects convergence. | Network topology \(( \rho )\) impacts convergence. |
source: Distributed Learning Systems with First-order Methods
Now since we know the motivation and the problem, I would like to dive deeper into DiLoCo paper published by DeepMind in September 2024.
DiLoCo: Distributed Low-Communication Training of Language Models
I chose the following paper because of its simplicity.
The paper DiLoCo: Distributed Low-Communication Training of Language Models talks about scaling up the training of language models to non co-located devices.
The vision of the authors is to do a world-wide collaborative training of large-scale models. Academia pooling their resources, basically sum greater than the parts.
The world-wide distributed training should communicate less often. This requires independent optimization, the gist of Federated Learning.
We want infrequent communication over heterogeneous devices.
DiLoCo Algorithm Summary:
 source: Paper
source: Paper
- Inputs:
- Initial model \(\theta^{(0)}\)
- \(k\) workers
- Data shards \(\{D_1, D_2, \dots, D_k\}\)
- Inner optimizer (InnerOpt usually adam) and outer optimizer (OuterOpt usually nesterov momentum)
- Algorithm Steps:
- Outer Loop (for \(( t = 1 \dots T )\)):
- Iterate through outer steps.
- Worker Loop (for \(( i = 1 \dots k )\)):
- Initialize each worker’s model \(( \theta_i^{(t)})\) with the previous global model \(( \theta^{(t-1)} )\) which will train in parallel.
- Inner Loop (for inner steps \(( h = 1 \dots H )\)):
- Sample data \(( x )\) from shard \(( D_i )\).
- Compute the loss \(( L )\) based on the model \(( \theta_i^{(t)} )\) and data \(( x )\).
- Perform inner optimization: update \(( \theta_i^{(t)} )\) using InnerOpt and the gradient \(( \nabla L )\).
- Averaging Outer Gradients:
- Calculate the average gradient \(( \Delta^{(t)} )\) across all workers.
- Outer Optimization:
- Update the global model \(( \theta^{(t)} )\) using OuterOpt and \(( \Delta^{(t)} )\).
- Outer Loop (for \(( t = 1 \dots T )\)):
- Repeat until all ( T ) outer steps are completed.
Fault Tolerance
The paper mentions about adaptive compute pool which is great but doesn’t talk about network failures in detail. It mentions - since they need to communicate less often, they can tolerate network failures. This may not be sufficient in real-world scenarios.
Adaptive Compute - They vary amount of compute available across time and they observed that the models generalize equally well.
Models quality is affected by the total amount of compute, but not as much by how such computed is allocated over time.
Limitations
- Transformer specific
- Only talks about training language models
- Only talks about models of scale up to 400 million parameters. The sota models are in the billions.
- Assumes all workers to be homogeneous.
- Diminishing returns beyond 8 workers.
DiLoCo is a robust and effective way to distribute training of transformer language models when there are several available machines but poorly connected. Of course, it remains to be seen whether these findings generalize to models of larger scale, or to other domains and architecture types.
CocktailSGD: Fine-tuning Foundation Models over 500Mbps Networks
In the previous post part 2, we talked about the challenges in distributed training communication and how 1Gbps networks are not enough for training large models. Hence, CocktailSGD caught my attention.
CocktailSGD compresses communication aggressively using a combination of top-K sparsification, quantization, and random sparsification.
Key Ideas -
- Asynchronous Training: Parallel compute and communication threads on each GPU node.
- Dual Model Copies: Local model for gradients, global model for synchronization.
- Error Compensation: Global error buffer tracks compression differences.
- Gradient and Model Difference: Workers compute both for updates.
- Compressed Communication: Bidirectional compression of model differences.
- Efficient Parallelism: 1-step staleness with hidden communication time.
- Iterative Synchronization: Regular local and global model updates until convergence.
 source: Paper
source: Paper
CocktailSGD Compressor -
- Multi-Dimensional: Balances sparsity, precision, and staleness.
- Three-Step Process: a. Random sampling (probability p) b. Top-K selection c. q-bit quantization
- High Compression: e.g., 100x with 10% sampling, 1% Top-K, 4-bit quantization
Convergence:
- Errors from random sampling are outweighed by compression benefits
- Hybrid method maintains acceptable convergence despite not always selecting most critical gradients
 Source: Paper
Source: Paper
Conclusion
Decentralized training of deep learning models is a fascinating area of research. It’s a step towards democratizing AI and making it accessible to everyone. If you want to explore more in this area, I would recommend reading - CocktailSGD, DiPaCo etc.
I hope you enjoyed reading this post. If you have any questions or feedback, feel free to reach out to me on email - vaibhaw [.] vipul [@] gmail [dot] com.
Thank you for reading!